
With the development of online services and the emerge of numerous financial products on the market, the number of companies ready to render these services also increases dramatically every year. Industry leaders give high priority to product parameters and characteristics, customer experience, clients' base expanding and keeping the loyal customers. The reverse side of this process is increasing complexity of clients risk assessment via online channels as well as rather large proportion of high risk users, who sometimes may come to the website of a financial institution with malevolent intentions. Thus, companies have to divert a significant share of resources (data collection, technology, staff) to reduce risks and to detect fraudulent users.
Along with the development of the companies doing business online, a large number of different vendor companies have entered the market. They provide solutions designed for reduction of the risk of fraud. Many of these solutions provide a set of risk markers that can be used to block some types of applications in application flow. However, this approach has several flaws.
JuicyScore team believes that apart from providing the markers themselves, it is also necessary to pay great attention to the information value and methodology of data usage regarding the risk assessment process. We have developed a number of methodologies and approaches that allow us not only to identify high-risk segments, but also to perform segmentation and risk assessment throughout the entire application flow. Today we will provide you detailed information about one of these approaches.
The essence of JuicyScore fraud prevention approach basing on devices detailed analysis
In our case, we examine approach to fraud prevention based on devices characteristics.
This methodology is based on a great focus on the device - accurate and precise authentication, identifying the various parameters that characterize the device, its environment and how it is used. But why do we pay so much attention to the device itself?
- The most obvious reason is related to the fact that often such assessment may be enough for making a decision about financial product application. While there is no need to store or process users' personal data (natural persons direct identifiers, such as full card numbers, photos, emails, passport data etc.) Despite of huge investment of the companies to the IT-infrastructure as well as organizational measures, cases when direct identifiers, contact information and sensitive data fall into fraudsters' hands are, unfortunately, quite common. This may lead to the loss of information, cause damage to reputation and result in financial losses to all parties. The second advantage of this methodology is predictive power - device analytics allows to assess the risk of all Internet connections with a level of information availability of 99.9% + and identify the virtual user intentions in most cases at the first attempt.
- The core of our approach within this methodology is careful and accurate device authentication taking into account device randomization and virtualization. This methodology is based on the developed set of instruments/ technologies for device metrics - a stable, probabilistic approach to device authentication.
- A support element of this technology is a set of instruments which allows to identify different variations in the randomization and virtualization of devices (as aspects of distortion in the process of device authentication). Virtualization issues have recently been in the spotlight of many experts' attention and today we would like to give you detailed information about JuicyScore approach to assess risk on device virtualization and randomization as well as discuss some aspects that online business owners need to pay attention to.
Which device categories we distinguish?
If we represent the entire probability space as a devices projection, we can distinguish the following categories, which cover 4 types of devices. There are physical devices, virtual devices (virtual machines), physical devices with randomization and virtual devices with randomization. Let's dive deeper into these categories that you can see on the picture below.
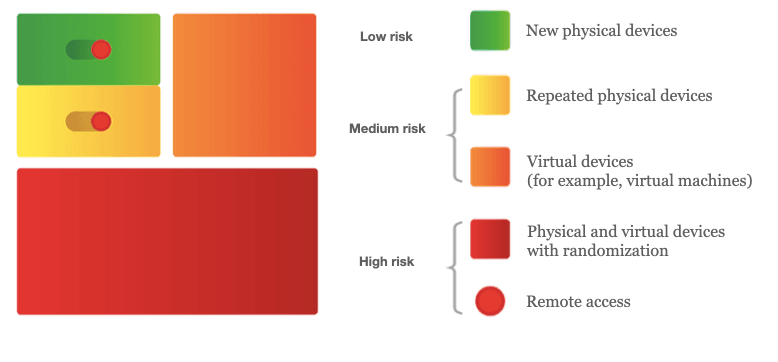
- Physical device in our paradigm is used when a person applies for obtaining a financial product or user's personal account login. Most common laptops, smartphones with more or less typical software without any serious anomalies in software or program components may be regarded as such type of device. Within the category of physical devices we also distinguish new and repeated devices - the risk level of repeated ones may, in some cases, differ significantly from the level of risk of the new ones.
Repeated devices are distinctively marked devices, for example, when the device was used in order to apply for a loan and some indicators of fraud were identified or payday loan has been in delinquency for more than 90 days. In such case it may be a second attempt to apply for a loan.
2. Virtual device is a virtual machine deployed on a physical device, that is used for nontypical activities of a user with unknown intentions. Usually such virtual devices may be either not designed for making operations connected with financial activities (for example, to apply for a loan or a credit), or may relate to grey legal area.
What is a virtual device or machine? It is any type of device (PC, tablet PC, smartphone etc.) created with special software or program code. In fact, such device doesn't differ from any physical computer/laptop/smartphone or even a server. It also has a processor unit, memory module, data and file storages, and it also can connect to the Internet if needed. However while real computers have physical storage system, memory modules and microprocessor chipsets, virtual machines or software-defined computers exist only as a code. Virtual machine may be a great instrument for dealing with issues related to data protection and safe program delivery, code testing, software performance research.
Virtual device make company's IT-infrastructure operations much easier and also increases productivity due to resource optimization. The use of such technologies in financial products and services obtaining may indicate user's malicious intentions and, therefore, may lead to high risk for the business.
3. Speaking of randomization we imply the use of any software or code used for adding various anomalies for device fingerprint obfuscation or user activities concealment. One can randomize a physical device or add some interference to virtual device (in terms of our categories description).
4. Randomized virtual devices is the most sophisticated type of fraud, which requires high technology skills. In this study we don't consider this type of devices in detail, as well as the aspect of network connection randomization. From the point of view of practical fraud prevention, it is more important to identify the randomization technologies on the device, which, in most cases, is enough for making a decision. Using randomizers in order to simulate the operation of network connection as well as code testing is absolutely normal, however using this software to apply for financial products and visiting the websites of online lenders is hard to consider as normal human activities.
The presented approach allows to cover the entire device probability space completely and also very thoroughly specify segment and assess risk. As we can see from the picture above, physical devices have the lowest relative risk of fraud, while repeated devices among physical ones may have a higher risk. Such devices can be assessed in terms of credit risks and, in some cases, with facilitated verification. Virtual devices are highly risky and, therefore, additional verification/validation should be carried out. Devices with randomization are the most dangerous in terms of risk and we recommend to deny such applications.
The appeared simplicity on the surface will perhaps be less so, if we dive deeper into sophisticated technologies. First of all, there is not a single device beyond the above mentioned segments. Therefore, this approach lets us to capture the whole picture. Secondly, this approach may be characterized as really sustainable and high effective, validated by our work experience in 20+ countries all over the globe.
How our technologies help to assess risks?
Index variables is an essential part of JuicyScore data vector attributes. We payed great attention to them in one of our previous articles - Deep Machine learning: on the path to the truth. But how exactly we can assess risk using JuicyScore data? In order to understand technological essence of our approach better, we need to look at a few variables (or variables of the IDX type in our standard data vector), which we create using the algorithms of deep machine learning.
IDX1 is a combination of 50+ rare events, which show high probability of fraud through technical manipulation of the device. This variable includes the whole variety of device randomization tools, techniques of interference into "digital fingerprint" as well as determines the most dangerous markers of user high risk behaviour and network connection markers. The variable can be used both in rules and also as a component of a fraud prevention model to identify the most dangerous customer segments. The risk level raises along with the parameter value, high values may be used as filters for automatic denial.
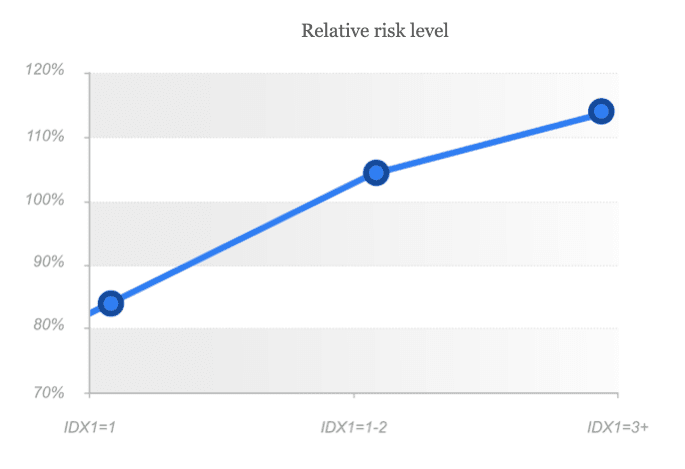
As we can see from the graph, variability indicator 0 means low risk, 1 - middle risk, when additional verification/validation should be carried out, indicator 2+ means high risk level and in such cases we recommend to deny such applications.
Apart from the use of randomizers, which are identified with IDX1 as well as with the separate stop factors - for example, copying of another device's session (vector's variable session clone), identification of anomalies in the header of the web session (vector's variable UserAgent Issue), indication of manipulation with the color palette (variable Canvas blocker) - also great attention should be paid to browser or operating system anomalies.
IDX3 is a combination of secondary risk markers and device anomalies, where every single anomaly may reflect possible risk, which should be taken into account during the borrower's verification. The combination of such markers highlights a high risk segment. Similarly to IDX1, the risk level is raising along with the variable value, and high values may be used for automatic denial.
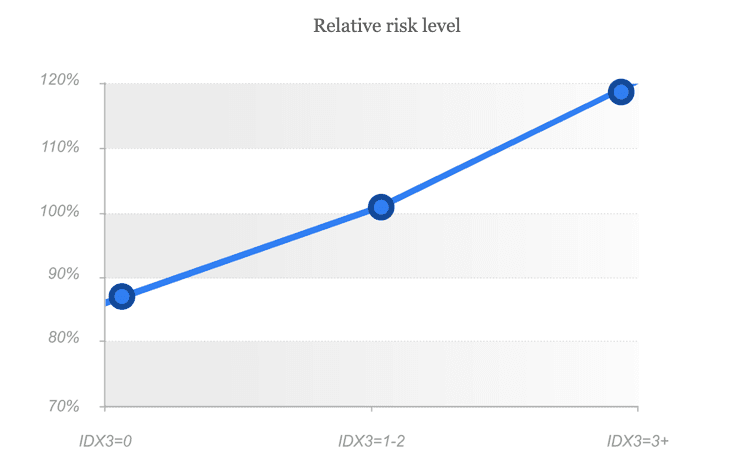
As we can see from the graph, variability indicator 0 means low risk, 1 - middle risk, when additional verification/validation should be carried out, indicator 2+ means high risk level and in such cases we recommend to deny such applications.
Cross-tabulation of various indexes values may also provide some important information on risk level. For example, if IDX1 and IDX 3 are equal to 0, thus there is a high probability that no randomisation and virtualization are identified, and we are dealing with a physical device.
This is just a small illustration of the practical approach toы randomization and virtualization detection technologies and their use in risk assessment and fraud prevention.
Currently the most informative and successful antifraud solutions have to meet the requirements commonly accepted by the industry:
- Real time fraud risk detection: hundreds of fraudsters can attack a financial institution's resource in a short period of time;
- High data information value - in order to improve the quality of decision making systems;
- Analysis of user behaviour and verification of hidden correlations.
However, as we all know, in antifraud and risk management there is no single and universal approach that would solve any problem and give 100 percent result. JuicyScore team believes that every new self-sustainable approach will find it's place.